双重差分(DID)
DID因果推断
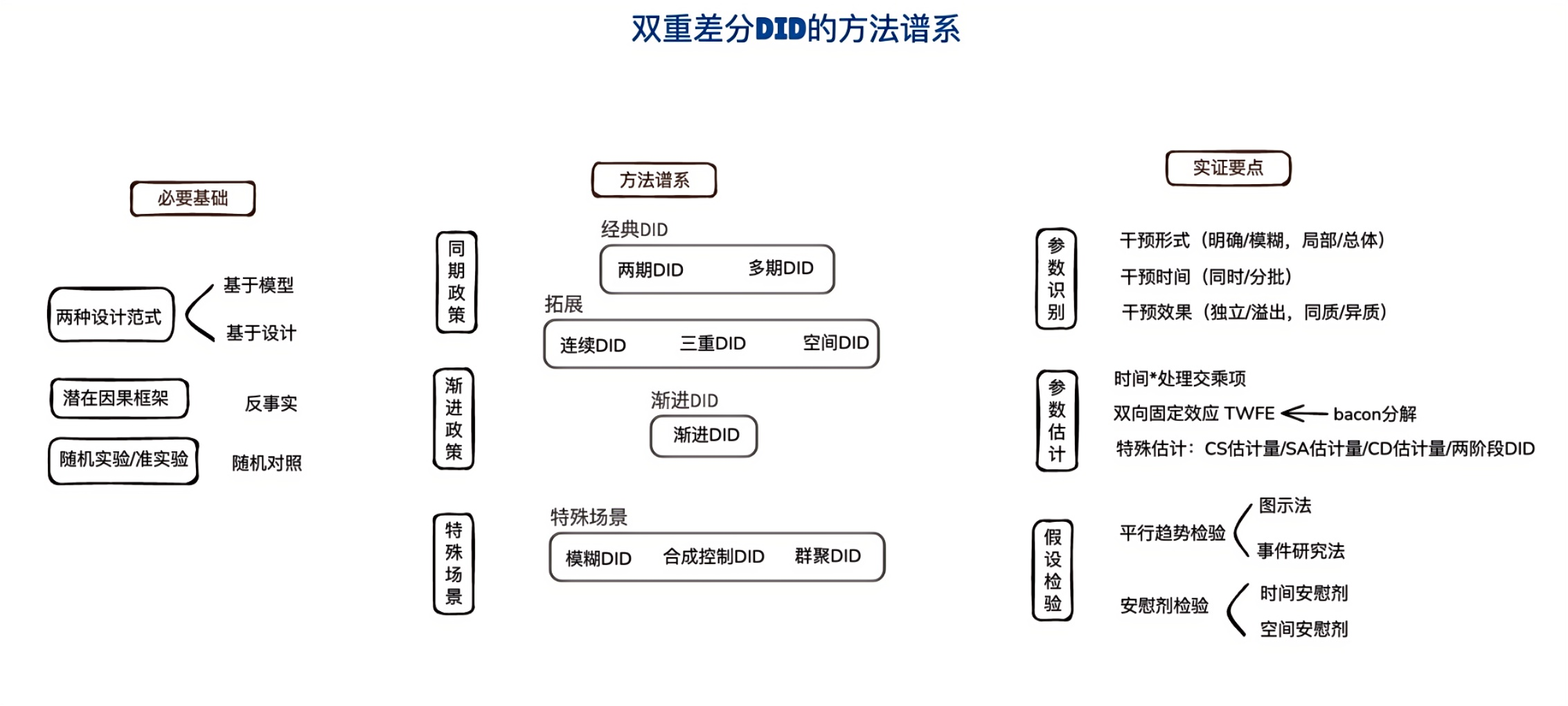
2_DID 的方法谱系
作者:数据范儿_范老师发布:2026-04-22更新:2026-04-22★★★
DID 的方法谱系:学习路线与知识框架
双重差分法(DID)在过去十几年中经历了快速的方法论发展。从经典的 2×2 设计到渐进 DID,从 TWFE 估计量到 CS/SA/BJS 等新估计量,DID 的方法体系已经形成了一个庞大而系统的谱系。
DID 方法全景图
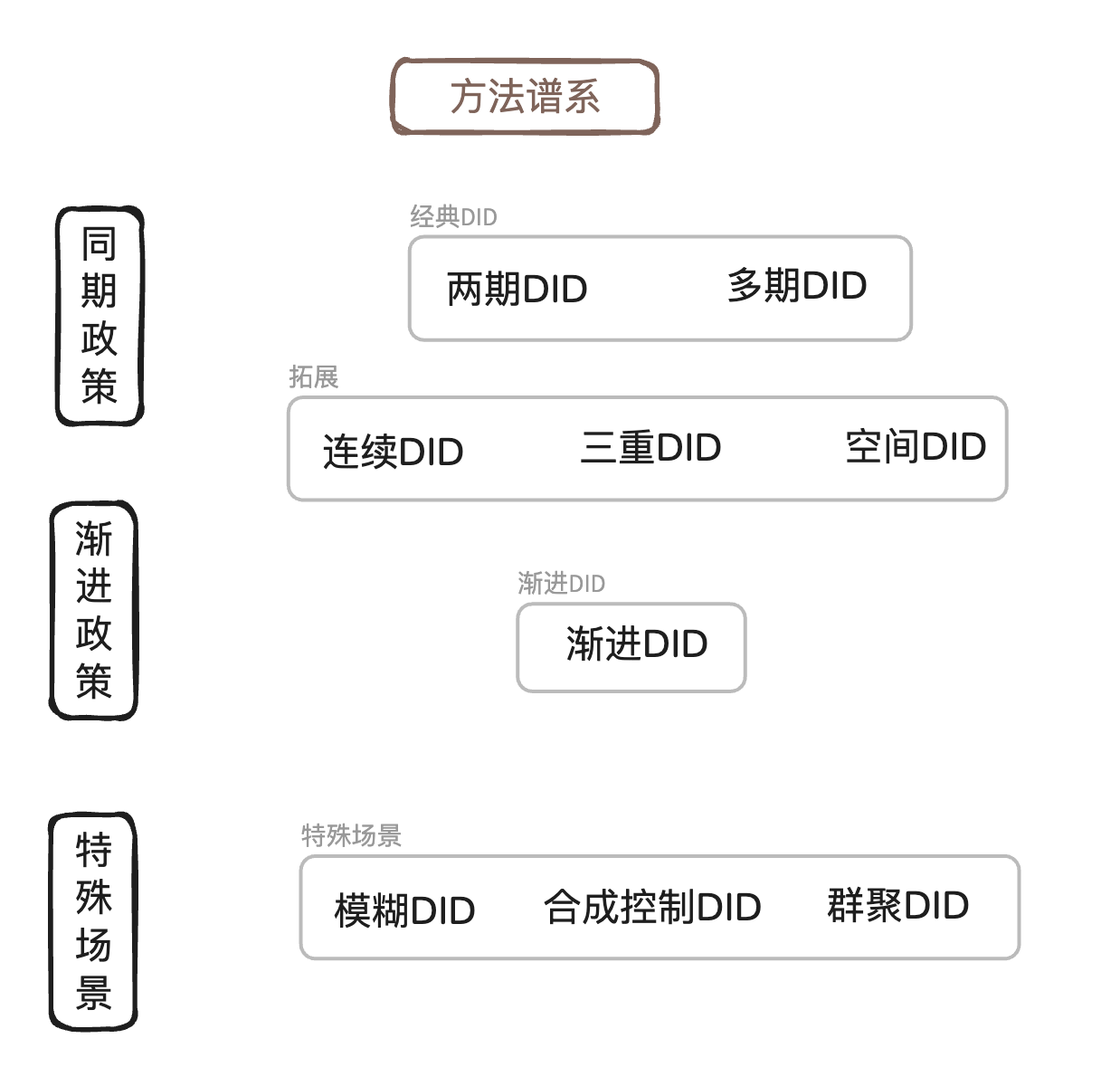
上图展示了 DID 方法的完整谱系,包括以下核心模块:
1. 经典 DID 框架
- 标准 2×2 双重差分
- 双向固定效应(TWFE)估计
- 平行趋势检验
- 安慰剂检验
2. 渐进 DID(Staggered DID)
- 多期多组处理设计
- 传统 TWFE 的偏误来源
- Bacon 分解:理解负权重与坏控制组
- 权重构造机制
3. 新估计量
- Callaway & Sant'Anna (CS) 估计量:基于组别-时期的 ATT 加权
- Sun & Abraham (SA) 估计量:事件研究框架下的交互加权
- Borusyak, Jaravel & Spiess (BJS) 估计量:基于未处理样本的 TWFE
4. 模糊 DID
- Wald-DID 估计量
- Wald-TC 估计量
- 单调性与局部平均处理效应(LATE)
5. 其他变体
- 强度 DID(连续处理变量)
- 空间 DID(考虑空间溢出效应)
- 合成 DID(SDID)
实证研究要点
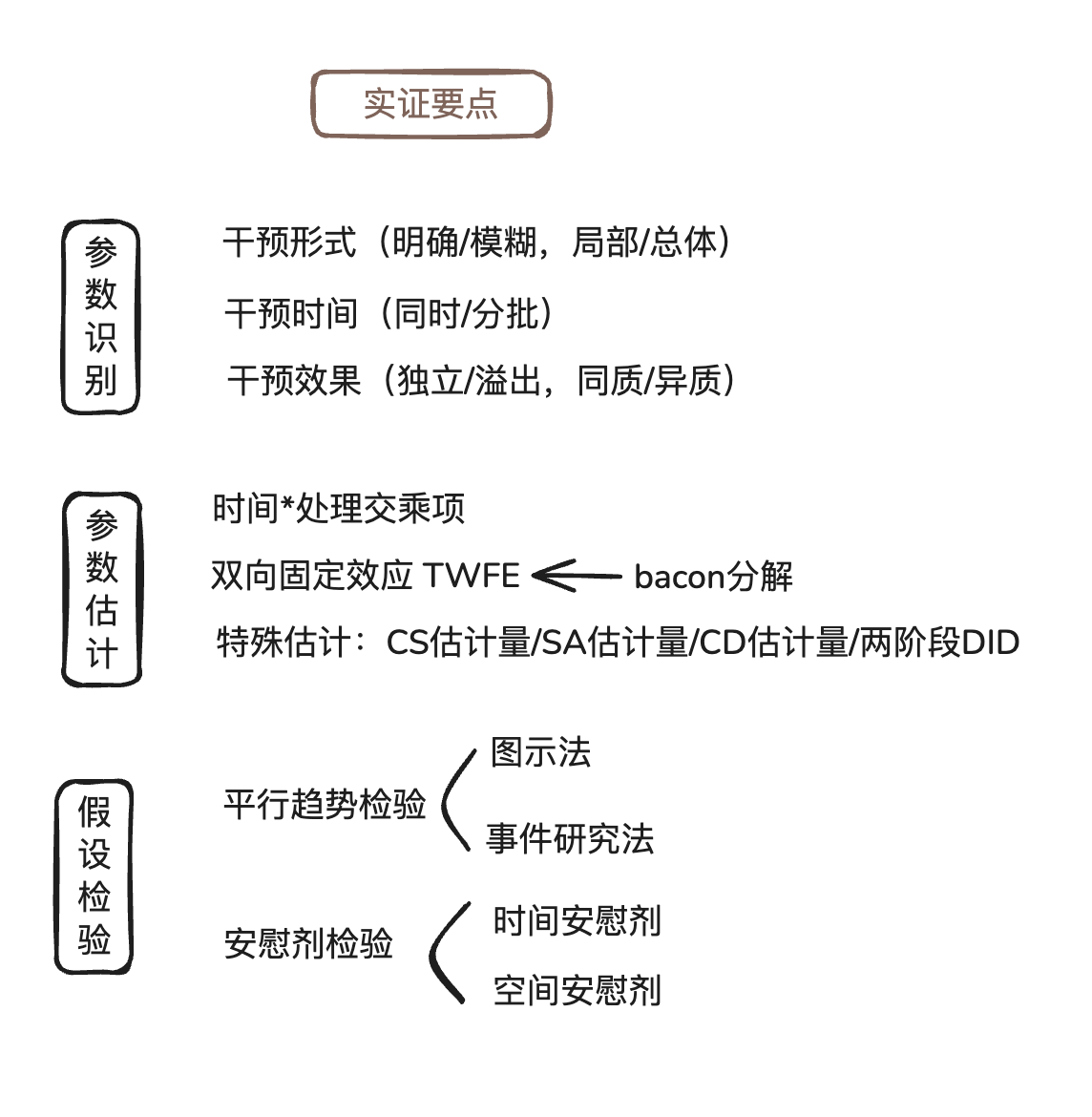
进行 DID 实证研究时,需要关注以下关键环节:
- 识别策略:处理变量是否外生?是否存在预期效应?
- 平行趋势:处理前处理组和控制组的趋势是否一致?
- 估计方法:选择合适的估计量(经典 DID / CS / SA / BJS)
- 稳健性检验:安慰剂检验、替换样本、更换模型设定
- 异质性分析:处理效应是否因群体、时间、地区而异?
学习路径建议
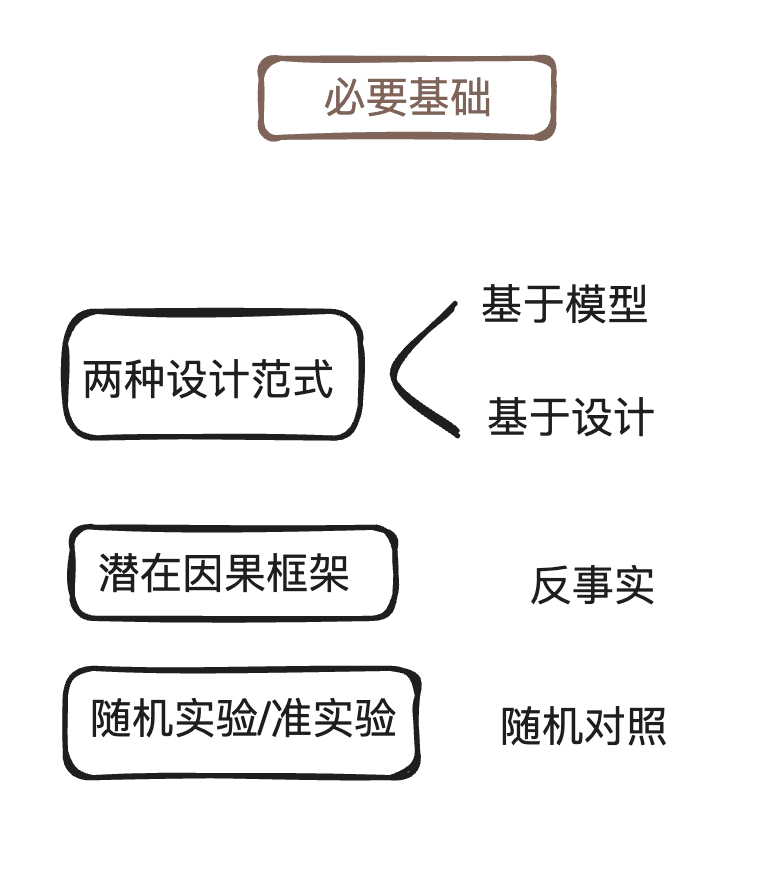
第一步:掌握基础概念
- 潜在结果框架与因果效应定义
- 观测研究 vs. 实验研究 vs. 准实验
- OLS 回归与固定效应模型
第二步:理解经典 DID
- 2×2 设计的识别逻辑
- 平行趋势假设的含义与检验
- TWFE 估计的推导与解释
第三步:深入方法变体
- 渐进 DID 的偏误与校正
- 新估计量的构造与比较
- 模糊 DID 与强度 DID
第四步:实践应用
- 选择合适的估计方法
- 进行完整的稳健性检验
- 合理解释与报告结果
方法选择决策树
根据研究设计的特点选择合适的方法:
- 简单 2×2 设计(一组处理、一个时间点)→ 经典 TWFE
- 多期多组设计(处理时间不同)→ CS / SA / BJS 估计量
- 处理强度连续变化 → 强度 DID
- 处理分配不完全随机 → 模糊 DID
- 存在空间溢出效应 → 空间 DID
核心要点
- DID 不是单一方法,而是一个方法家族,每种变体适用于不同的研究设计
- 经典 TWFE 在渐进 DID场景下会产生偏误,需要使用新估计量
- 实证研究的核心在于识别假设的合理性,而非估计方法的复杂程度